
Understanding user intent through content
March 16, 2018
Why? Understanding, predicting, and acting on customer intent is necessary to guide users along their journey. Let’s express intent as a function of two things:
Intent = Engagement + Context.
Engagement is the easy part of that equation because all of your users tell you how engaged they are — you just have to make sure you’re listening. We’ve already discussed how to use behavioral scoring to understand your users’ engagement, so we won’t go into that in depth here.
The part that is difficult for a lot of us is the context — what are they engaging with and how are they engaging with it. In the equation, if you want to increase customer intent, increase the relevancy of the context around engagement, which will increase the engagement as well. Increasing your relevancy triggers a virtuous cycle.
Here we’ll talk about how to use your existing content to build an Intent Graph to help you always stay relevant with your users to maintain and improve engagement.
The holy grail of content modeling
To better understand our content, we’ll need to build out a content model.
An on-the-ball content modeler has probably, at some point, painstakingly mapped their content schema to a specification like Schema.org. Anyone who has done this knows (through a painful, sad experience) that this is hard because (1) content is inherently nuanced and (2) topics are likely to evolve over time.
Now imagine that, in an ideal world, you had access to the Holy Grail of Content Modeling: an automatically-generating, self-updating content model that represents every topic in a domain with its hierarchical relationship to other topics. Side note: we work for a place that does this well.
Here we’ll walk through how such a content model — a Topic Graph — is built and how to use it in your workflow. But first we need to cover some basics.
Graphs 101
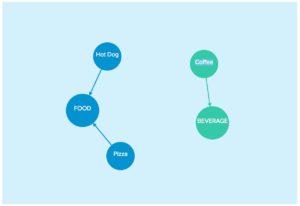
We’ll frame our discussion of topic models in terms of mathematical graphs, which helps us express how two things are related. We’ll call a thing a node, and we’ll call a relationship between two things an edge.
That’s all a graph is: nodes and edges.
Let’s consider some everyday relationships we can represent in a graph:
- A Pizza is Food
- A Hot Dog is Food
- A Coffee is a Beverage
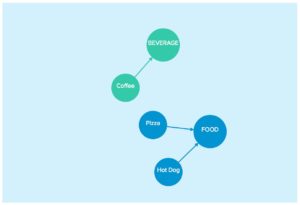
If we want to get fancier, we can add weights to the edges, which can measure the strength of the relationship. Here’s the same graph, but with edge weighting, where larger edge weights indicate stronger relationships. We’ll let all of the edges equal 1, except for Hot Dog to Food, which we’ll let equal 0.4. In the graph, weaker relationships have more opaque lines. (DISCLAIMER: I don’t like hot dogs.)
In reality, our topic graph will consist of more than just Pizza and Hot Dogs. We’ll mine our own troves of content to extract the topics that are relevant to our own content and users’ interests.
Topic classification
Topic classification is part of a broader study the field in computational linguistics known as natural language processing (NLP). If you’re looking for NLP vendors providing topic classification services, you will not have trouble finding them.
For most marketers, content is manifested in the form of web pages and messages (like email, rich push, in-app messaging, etc.). As users engage with content over time, we can start to gauge their preferences for certain topics. Each topic can be thought of as an independent tag — an article about Milli Vanilli might be tagged with both the topics “scandal” and “music.”
The beauty of a pure tag topic model is two-fold: (1) we can aggregate tags from multiple sources to create an even richer graph of topics, and (2) we can also bring in new topics as they emerge in the content.
However, an increasingly rich graph of topics can quickly become an increasingly complex graph of topics. A truly meaningful understanding of topics in the graph requires an understanding of the hierarchy of the topics.
Graphing topics
In reality, the breadth of our tagging universe is very large, but not all tags are created equal. Some are very specific, while others are more abstract. Some occur frequently, others infrequently.
We can determine tags are related by evaluating how they occur together and how they occur independently. Let’s go back to food and consider tags that are likely to occur on a recipe sharing site: BBQ, Gluten-Free, Baking, etc. We’ll represent them as nodes in our graph and initially have no reason to assume they’re related.
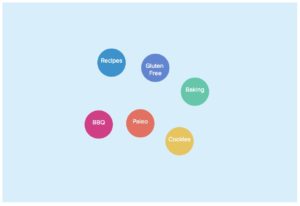
As users consume more content, we start to understand the hierarchy between topics — “Cookies” is a dependent topic of “Baking,” which is a dependent topic of “Recipes.”
How could we arrive at that conclusion without any human intervention?
The “Baking” tag occurs in instances where “Cookies” doesn’t occur, but there aren’t many instances where “Cookies” occurs without the tag “Baking.” That asymmetry tells us that “Cookies” is a tag that is dependent on “Baking” and should be represented as such in our graph.
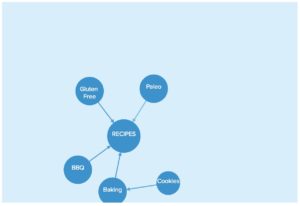
That understanding would inform us that a user with lots of “Cookies” and “Cakes” tags might show more affinity for the “Baking” topic, than either the “Cookies” or “Cakes” topics in particular.
Most topics evolve over time. If we knew a user was interested in Pie recipes, an outdated model might recognize Mince Pye as a related and dependent topic and make some subsequent recommendations. An up-to-date model would hopefully be making much more relevant recommendations.
Lytics on Lytics
As an example of what a Topic Graph might look like, here’s a sample of ours! Visualizing arbitrarily large graphs can quickly become more distracting than helpful, so we limited this sample on tags extracted from 100 URLs from traffic on our site.
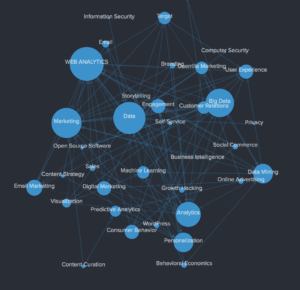
Using an intent graph in your workflow
An Intent Graph, like those that can be leveraged by Lytics customers, couples a Topic Graph with user engagement data. There are a couple of ways you can immediately start getting value out of your Intent Graph:
- Onboarding: Discover the topics that your most active users are engaging with. Apply those topics to nurture campaigns as you guide those users that are still early in their lifecycle.
- Identify pools of global topic affinity: Looking at beautiful visualizations of your topic graph is much different than looking at topic affinity across users. Does the content you’re producing line up with the affinities that your users are demonstrating? A high-level breakdown of topic affinity can inform a much more effective content strategy.
- Identify topic affinity by user segment: Do you know which affinities your best users are demonstrating? How about your worst? Are they different? The answers to those questions could make for more effective win-back and upsell campaigns.
- Personalization: Feed topic affinities to your favorite personalization tools to personalize in a way that users actually care about.
And those are just starting points. As you become more familiar with your own Intent Graph, you’ll find new ways to leverage it and stay relevant to your users.
So start building your graph. Or, let us build it for you. We don’t mind.
Want to dig deeper? We’d love to talk!
Footnotes
Using an unweighted Topic Graph can be dangerous. Consider an anecdotal example: Is Michael Jordan a basketball player or a baseball player? Wikipedia says both. While that’s technically true, you’d be crazy to say he’s equally related to both basketball and baseball.
The co-dependence between topics will naturally vary from dataset to dataset. For a site like TechCrunch, “Disrupt” might be very closely related with “Innovation”. For a site like WebMD, “Disrupt” is likely related to much different topics.
Note that some topics are not of the same types of other topics. You could argue that the “Italian” and “Vegetarian” topics for recipes aren’t of the same type and shouldn’t be represented in the same hierarchy — some Italian recipes are vegetarian and others aren’t. Using a graph to model hierarchies allows the co-existence of multiple hierarchies in the same graph. Using an empirical approach, like the one outlined here, means that topic will be connected only if a dependence actualizes in the data, and we don’t have to worry about the implications or nuances of separating hierarchies.
There exists some debate about a slightly false dichotomy for how to automate content selection. Whichever way your philosophy swings, you’ll find that these kinds of Intent Graphs that map back to user interests support both methodologies.

